Mi Stack para Integrar IA Local en Aplicaciones Web: Dify + Ollama + Qwen3
Una guía práctica sobre cómo integrar asistentes de IA en aplicaciones web usando Dify selfhosted y Ollama con modelos locales, con ejemplos reales del blog que estás leyendo y el paradigma de tratar a la IA como una función programable.

Mi Stack para Integrar IA Local en Aplicaciones Web: Dify + Ollama + Qwen3
Cuando hablamos de integrar IA en nuestras aplicaciones, muchos piensan inmediatamente en APIs de OpenAI o Claude con sus costos por token. Pero existe otra forma: correr modelos localmente con control total sobre tus datos y costos fijos. Hoy te muestro el stack que uso en este mismo blog que estás leyendo, con dos asistentes de IA funcionando en tiempo real.
Los Asistentes de IA de Este Blog
Si estás leyendo esto, ya tienes acceso a dos implementaciones reales de este stack. El primero es el sistema de recomendaciones en la página principal:
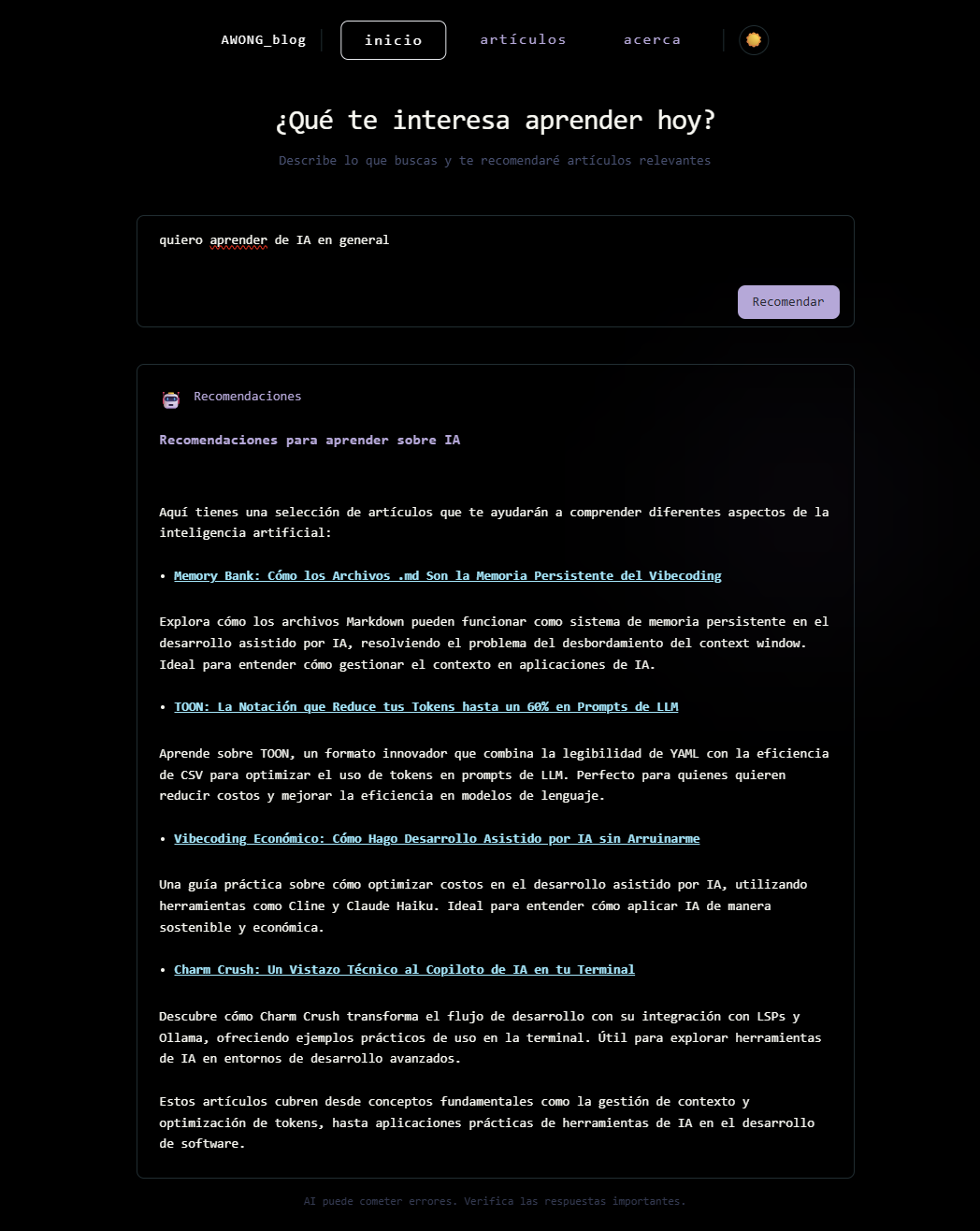
Escribes qué quieres aprender o un tema específico, y el asistente te devuelve recomendaciones personalizadas de posts relevantes con enlaces directos. No es magia: es contexto estructurado.
El segundo asistente aparece cuando lees cualquier post en versión desktop:
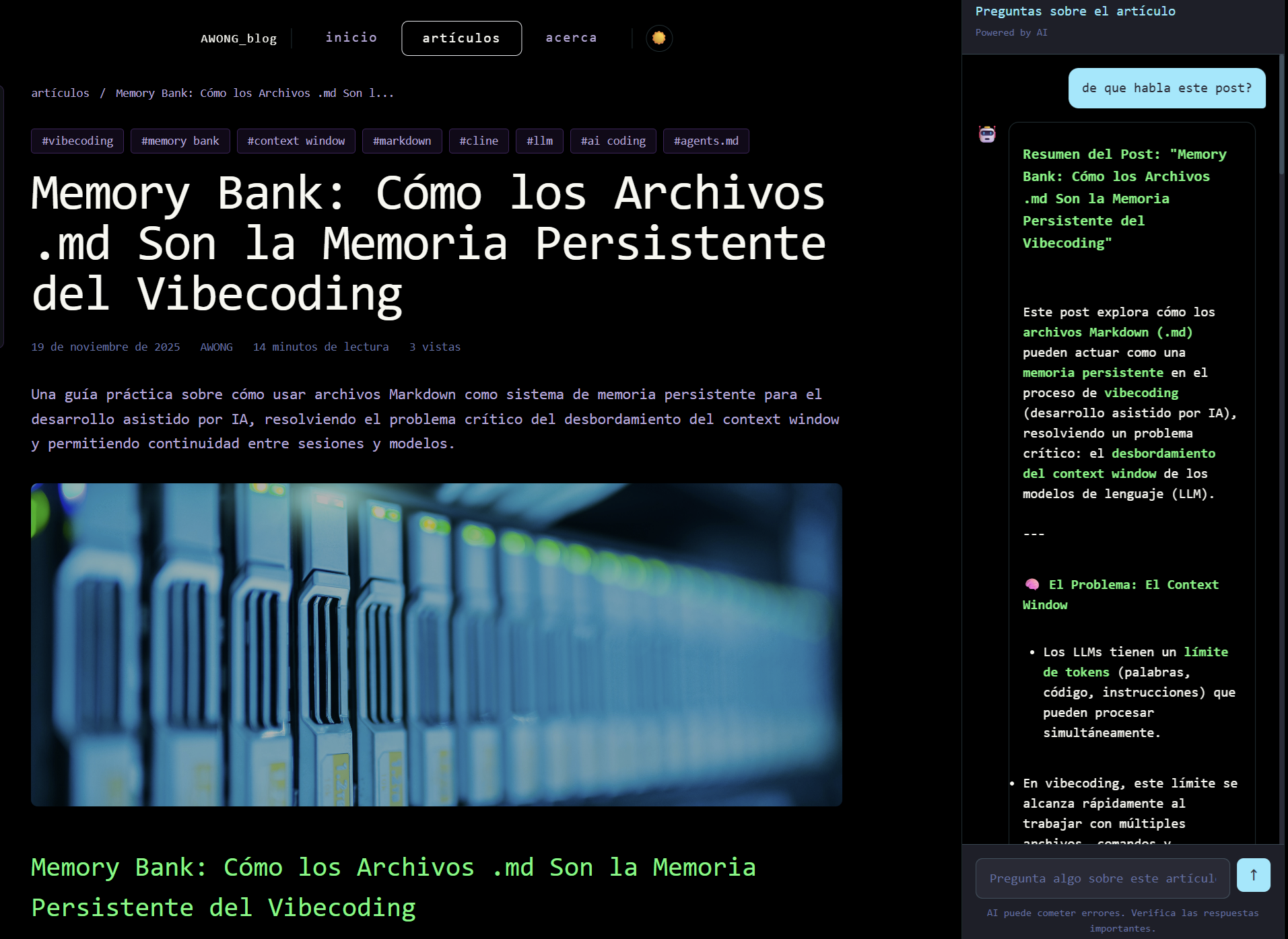
Este copiloto te permite hacer preguntas sobre el contenido, pedir resúmenes, solicitar ejemplos adicionales o profundizar en conceptos específicos. Tiene el contexto completo del artículo que estás leyendo.
El Cambio de Paradigma: La IA como Función
Aquí está el concepto clave que quiero que te lleves de este post: no siempre le tienes que mandar a la IA solamente el prompt del usuario. Hay que tratar a la IA como una función de programación que puede recibir diferentes parámetros.
Piénsalo así: cuando llamas una función en código, no le pasas solo el input del usuario. Le pasas configuración, contexto, datos de la base de datos, estado de la aplicación. Con los LLMs es exactamente igual. El prompt del usuario es solo uno de los parámetros que puedes enviar.
En mis implementaciones, envío estructuras JSON completas que incluyen la lista de posts disponibles (para recomendaciones), el contenido completo del post actual (para el asistente de lectura), instrucciones específicas de comportamiento, y el prompt del usuario como un campo más del objeto.
Esto transforma al LLM de un "chatbot genérico" a una función especializada con contexto rico.
El Stack: Dify + Ollama + Qwen3
¿Por Qué Este Stack?
Elegí estos componentes por razones específicas. Dify porque es una plataforma open-source que simplifica la orquestación de LLMs con una interfaz visual para diseñar agentes, manejo automático de conversaciones, y API lista para producción. Ollama porque permite correr modelos localmente con un solo comando, exponiendo una API compatible con OpenAI. Qwen3:14b porque ofrece un balance excelente entre capacidad y recursos, con soporte multilingüe nativo incluyendo español.
Arquitectura General
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Frontend │────▶│ Dify │────▶│ Ollama │
│ (JavaScript) │◀────│ (Orquestador) │◀────│ (Qwen3:14b) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
Envía JSON Gestiona Procesa
estructurado conversación inferenciaQuickstart: Instalando Ollama
Ollama es sorprendentemente fácil de instalar. Descarga desde https://ollama.com/download para tu sistema operativo. En macOS puedes usar brew:
# macOS con Homebrew
brew install ollama
# Linux
curl -fsSL https://ollama.com/install.sh | sh
# Windows: descarga el instalador desde ollama.comUna vez instalado, inicia el servicio:
# Iniciar el servidor de Ollama
ollama serveEsto levanta una API en http://localhost:11434. Ahora descarga el modelo Qwen3:14b:
# Descargar Qwen3 14B (9.3GB)
ollama pull qwen3:14b
# Verificar que se instaló
ollama list
Puedes probar el modelo directamente:
# Test rápido
ollama run qwen3:14b "Explica qué es una API REST en una oración"El modelo Qwen3:14b tiene 14.8 billones de parámetros con cuantización Q4_K_M, requiere aproximadamente 10GB de RAM/VRAM, y soporta un context window de 40K tokens. Para hardware más limitado, considera qwen3:8b (5.2GB) o qwen3:4b (2.5GB).
Quickstart: Instalando Dify con Docker
Dify se despliega mejor con Docker Compose. Primero clona el repositorio:
# Clonar Dify (usa la versión estable más reciente)
git clone https://github.com/langgenius/dify.git --branch 0.15.3
cd dify/docker
# Copiar archivo de configuración
cp .env.example .envInicia los contenedores:
# Iniciar todos los servicios
docker compose up -d
# Verificar que todo está corriendo
docker compose psDeberías ver 11 contenedores corriendo: api, worker, web, db (PostgreSQL), redis, nginx, weaviate, sandbox, y ssrf_proxy. Accede a http://localhost/install para crear tu cuenta de administrador.
Conectando Dify con Ollama
Aquí viene el paso crítico. Ve a Settings → Model Providers → Ollama y configura:
Model Name: qwen3:14b
Base URL: http://host.docker.internal:11434
Model Type: LLM
Context Length: 12000
Max Tokens: 4096
Support for Vision: NoImportante: Si Dify corre en Docker y Ollama en tu host, usa host.docker.internal en lugar de localhost. En Linux, puede que necesites usar la IP de tu máquina o configurar la red de Docker.
Si obtienes errores de conexión, asegúrate de que Ollama esté escuchando en todas las interfaces. En Linux, edita el servicio:
# Editar configuración de Ollama
sudo systemctl edit ollama.service
# Agregar bajo [Service]:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"Creando el Agente en Dify
Una vez conectado Ollama, crea una nueva aplicación tipo "Chat" en Dify. La configuración que uso tiene los siguientes parámetros clave:
Tipo: Chat
Modelo: qwen3:14b (Ollama)
Context Window: 12000 tokens
Temperature: 0.7
Top P: 0.95El context window de 12K tokens es suficiente para incluir posts completos más el historial de conversación. Ajusta según tus necesidades y la capacidad de tu hardware.
Implementación: Sistema de Recomendaciones
Veamos el código real que usa el blog para las recomendaciones. La clave está en cómo estructuro el JSON que envío a Dify:
async function sendRecommendation({ query, posts, conversationId = null }) {
try {
// Crear contexto de posts con enlaces
const postsContext = posts.map(post => ({
title: post.title,
url: `/posts/${post.id}`,
description: post.description,
tags: post.tags
}));
// JSON estructurado con instrucción + datos + query
const contextData = {
instruction: "Eres un asistente de blog que recomienda artículos. " +
"Basándote en la pregunta del usuario y la lista de posts disponibles, " +
"recomienda los posts más relevantes. Responde en español con markdown, " +
"incluyendo los enlaces a los posts recomendados usando el formato " +
"[Título](url). Explica brevemente por qué cada post es relevante.",
available_posts: postsContext,
user_query: query
};
const body = {
inputs: {},
query: JSON.stringify(contextData),
response_mode: 'blocking',
user: 'blog-visitor',
conversation_id: conversationId || ''
};
const response = await fetch(`${DIFY_API_URL}/chat-messages`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${DIFY_API_KEY}`
},
body: JSON.stringify(body)
});
if (!response.ok) {
throw new Error(`Dify API error: ${response.status}`);
}
const data = await response.json();
return {
success: true,
answer: data.answer,
conversation_id: data.conversation_id,
message_id: data.message_id
};
} catch (error) {
console.error('Dify Recommendation API error:', error);
return { success: false, error: error.message };
}
}Observa cómo el "prompt" real es un JSON stringificado que contiene las instrucciones del sistema, todos los posts disponibles, y la query del usuario como un campo más. El LLM recibe todo el contexto necesario para dar recomendaciones relevantes.
Implementación: Asistente de Lectura de Posts
Para el asistente que aparece mientras lees un post, la implementación es similar pero con contexto diferente:
async function sendMessage({ query, post, conversationId = null }) {
try {
// Contexto: post completo + pregunta del usuario
const contextData = {
actual_post: post,
user_prompt: query
};
const body = {
inputs: {},
query: JSON.stringify(contextData),
response_mode: 'blocking',
user: 'blog-user',
conversation_id: conversationId || ''
};
const response = await fetch(`${DIFY_API_URL}/chat-messages`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${DIFY_API_KEY}`
},
body: JSON.stringify(body)
});
if (!response.ok) {
throw new Error(`Dify API error: ${response.status}`);
}
const data = await response.json();
return {
success: true,
answer: data.answer,
conversation_id: data.conversation_id,
message_id: data.message_id
};
} catch (error) {
console.error('Dify API error:', error);
return { success: false, error: error.message };
}
}Y el system prompt en Dify para este agente:
Eres un copiloto para el blog de Andres Wong.
Recibirás un arreglo JSON con 2 llaves:
{'actual_post': ..., 'user_prompt': ...}
Debes asistir al usuario con sus preguntas acerca del actual_post.
Si no recibes la estructura correcta del JSON, no podrás ayudar
y deberás regresar un mensaje de error.
Tu respuesta tiene que ser siempre en formato markdown.Este system prompt establece el contrato: el agente espera un JSON específico y responde en markdown. Si la estructura no es correcta, falla explícitamente. Es programación defensiva aplicada a prompts.
Más Ejemplos de IA como Función
El paradigma de "IA como función" se extiende a muchos casos de uso. Aquí hay algunos ejemplos adicionales:
Análisis de Código con Contexto
const contextData = {
instruction: "Analiza el código y sugiere mejoras de performance",
code: sourceCode,
language: "javascript",
framework: "react",
performance_metrics: currentMetrics,
user_question: userQuery
};Generador de Emails con Tono
const contextData = {
instruction: "Genera un email profesional basado en los parámetros",
recipient_info: {
name: "María García",
role: "CTO",
relationship: "cliente potencial"
},
email_purpose: "seguimiento de demo",
tone: "formal pero amigable",
key_points: ["agradecer tiempo", "resumir beneficios", "proponer siguiente paso"],
user_notes: userInput
};Asistente de Debugging
const contextData = {
instruction: "Ayuda a debuggear el error basándote en el contexto",
error_message: errorLog,
stack_trace: stackTrace,
relevant_code: codeSnippet,
environment: {
node_version: "18.x",
os: "linux",
dependencies: packageJson.dependencies
},
user_description: userQuery
};En cada caso, el LLM recibe contexto estructurado que le permite dar respuestas específicas y útiles en lugar de respuestas genéricas.
Consideraciones de Producción
Manejo del conversation_id
Dify maneja automáticamente el historial de conversación a través del conversation_id. En la primera llamada lo envías vacío, y Dify te devuelve uno nuevo. En llamadas subsecuentes, envías el mismo ID para mantener el contexto.
// Primera llamada: sin conversation_id
const firstResponse = await sendMessage({ query, post });
const convId = firstResponse.conversation_id;
// Llamadas siguientes: incluir el ID
const followUp = await sendMessage({
query: newQuery,
post,
conversationId: convId
});Streaming vs Blocking
En los ejemplos uso response_mode: 'blocking' que espera la respuesta completa. Para mejor UX, considera usar streaming:
const body = {
// ... resto igual
response_mode: 'streaming'
};
const response = await fetch(url, options);
const reader = response.body.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
// Procesar chunks incrementalmente
const text = new TextDecoder().decode(value);
updateUI(text);
}Límites de Contexto
Con 12K tokens de contexto, puedo incluir posts de hasta ~8000 palabras más historial de conversación. Para posts más largos, considera truncar el contenido o usar técnicas de chunking con embeddings.
Costos y Rendimiento
Una de las grandes ventajas de este stack es el costo predecible. Una vez que tienes el hardware corriendo Ollama, el costo marginal por request es esencialmente cero: solo electricidad.
En mi setup (RTX 3080 10GB), Qwen3:14b genera aproximadamente 30-40 tokens por segundo. Para una respuesta típica de 200 tokens, son ~5 segundos. No es tan rápido como las APIs cloud, pero es consistente y sin límites de rate.
Si tu hardware es más limitado, considera usar qwen3:8b (5.2GB), qwen3:4b (2.5GB), o correr en CPU (más lento pero funcional).
Conclusión
El stack Dify + Ollama + Qwen3 te da control total sobre tus integraciones de IA con costos predecibles y privacidad de datos. Pero el verdadero insight es el paradigma: trata a la IA como una función que recibe parámetros estructurados, no solo como un chatbot que recibe texto plano.
Cuando envías contexto rico (posts disponibles, contenido actual, métricas, configuración) junto con el prompt del usuario, transformas un LLM genérico en una herramienta especializada para tu caso de uso específico.
Los dos asistentes de este blog son prueba de concepto: el mismo modelo Qwen3:14b, con diferentes contextos JSON, se comporta como un recomendador de contenido o como un tutor de lectura. La diferencia está en los parámetros que le pasas, exactamente como una función bien diseñada.
artículos_relacionados

El Cuerpo Importa Más que el Cerebro
Cierre de la serie cc_bridge: la pregunta incomoda de si el valor de Claude esta en el modelo o en su harness. Con claude-code-router probe cambiarle el cerebro a Claude Code; con cc_bridge lo volvi intercambiable. Ollama habla la API de Anthropic nativa, asi que minimax corrio whoami y ping de verdad. El cerebro es el motor; el cuerpo es el producto.

El Mes que un Agente de IA Me Costó 11,500 Pesos
Primer post de la serie cc_bridge: la busqueda del cerebro para mi agente autonomo con OpenClaw. Codex se quedo corto, Gemini Pro 4 me dejo una factura de 11,500 pesos en un mes, y lo barato no ejecutaba. La pregunta que destrabo todo: separar al que piensa del que ejecuta.

Dejé de Adivinar Qué Ollama Estaba Vivo: Así Nació ollamon
La historia de por que construi ollamon: un monitor de flotas de Ollama en Go que autodescubre cada instancia leyendo el kernel, porque opero infra que cambia sin avisar. Lee la GPU con NVML nativo y junta todo en una vista unificada. Nacido de un incidente real en produccion.